The superior temporal sulcus¶
Introduction¶
From auditory cortex in the posterior portion of the superior temporal gyrus we pivot downwards to the superior temporal sulcus, or STS, outlined in green in Fig. 93. It is the first sulcus down from the Sylvian fissure/lateral sulcus:
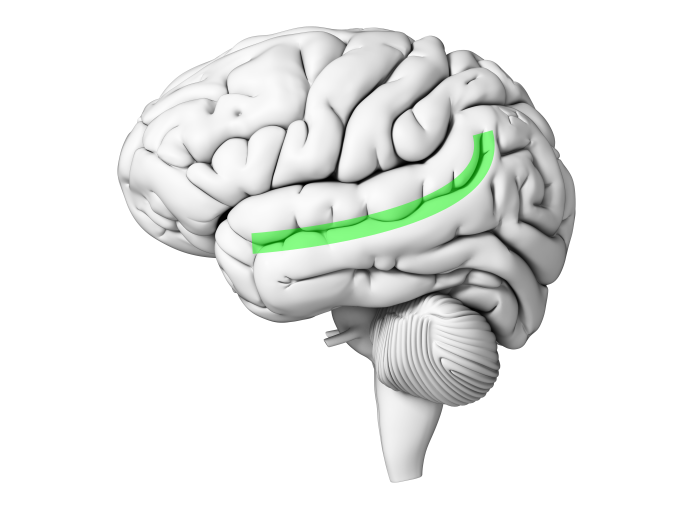
Fig. 93 The superior temporal sulcus, in green. Author’s image.¶
In the dual pathway model of [HP07], it is the next stop after the spectrotemporal analysis performed by the auditory cortex, highlighted in yellow:
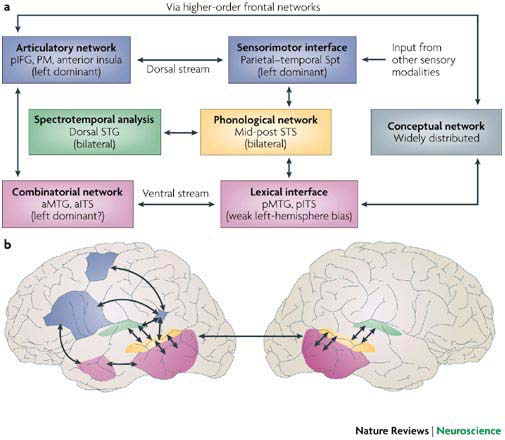
As you can see in the diagram, Hickok & Poeppel characterize the STS as a “phonological network”, on the basis of effects reviewed in Distinguishing speech from non-speech and Phonological neighborhoods. To make this a bit more concrete, I postulate that the STS constructs phonetic words. By “phonetic word” I mean simply the pronunciation of a word, like [kæt] for cat. This is different from treating cat as a morphological word, which would be a singular noun, or a semantic word, which would be a feline. The ventral pathway identifies [kæt] as a singular noun denoting a feline, but we are not there yet.
Distinguishing speech from non-speech¶
[] presented subjects with noise, tones, words, pseudo-words and reversed words while undergoing fMRI scanning. The STS was more active in both hemispheres in response to speech (the words) than to the tones. In a similar vein, [BZL+00] scanned subjects while they listened to speech (isolated words or spoken passages in several languages), human non-speech vocalizations (laughs, sighs and coughs), and non-vocalizations (natural or mechanical sounds and animal cries). Several areas along the STS were more active for speech with respect to non-speech sounds. In a second experiment, the same subjects heard a series of control sounds: bells, human non-vocal sounds (finger snaps and hand claps), white noise whose amplitude was varied to mimic speech, and scrambled voices. The STS still responded preferentially to human voices. Finally, the authors tried to ‘break’ the STS by removing the high and low frequencies from vocal and non-vocal sounds and asking the subjects to identify the voices. The subjects’ STS activation still peaked for vocal sounds, but its amplitude was lower for the filtered stimuli, and the subjects’ identifications were worse, suggesting that the STS struggled to perceive the filtered stimuli.
Since this seminal work, many other studies have investigated the distinction of speech and non-speech, enough to merit a meta-analysis. [HP07] compile the results of seven fMRI studies which contrasted speech with non-speech and plot them together on the pair of hemispheres below:
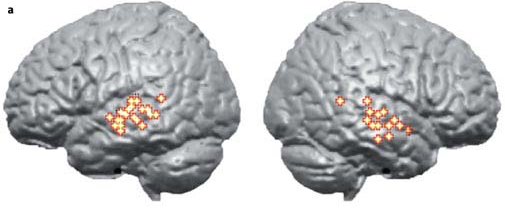
Fig. 95 Subtraction of non-speech from speech activations. [2]¶
Other¶
Warning
The following is not incorporated yet.
{Evans and Davis, 2015}
Within this hierarchy, speech-specific responses to isolated syllables are only observed in later stages of processing, primarily in the superior temporal sulcus (Liebenthal et al. 2005; Uppenkamp et al. 2006; Heinrich et al. 2008). While some of these findings might reflect acoustic differences between speech and non-speech stimuli, studies with SW speech have demonstrated that acoustically identical stimuli evoke additional responses in the posterior STS when they are perceived as speech (Dehaene et al. 2005; Möttönen et al. 2006; Desai et al. 2008). Similar regions of posterior STS (and adjacent inferior parietal cortex) are activated for categorical perception of syllables, for example, showing an additional response to sequences that include categorical changes, compared with repetition or within-category changes (Jacquemot et al. 2003; Zevin and McCandliss 2004; Joanisse et al. 2007; Raizada and Poldrack 2007). However, studies with non-speech analogs have also demonstrated additional activity in these regions when listeners are trained to perceive non-speech sounds categorically (Leech et al. 2009). Thus, it might be that posterior STS regions are activated for any kind of categorically perceived sound rather than representing speech content per se.
Lexical retrieval¶
Imagine that a dictionary is presented with the word beaker, phonologically /bikɹ/, and wants to look it up. There are two strategies for doing so. One is serial: the dictionary examines each sound in turn and checks to see whether it has an entry that begins with the current sequence. The other is – OK, you thought I was going to say “parallel” – more interactive.
A serial model of lexical retrieval¶
Imagine that the dictionary has two tools, one for recognizing phonemes and the other for comparing phoneme sequences to entries in its database. The process of recognizing /bikɹ/ would go something like this:
The phoneme detector detects /b/.
The comparator starts looking for all the entries that begin with /b/, perhaps ordered in terms of frequency.
The phoneme detector detects /i/.
The comparator rejects the entries that don’t begin with /bi/ and starts searching the remaining ones, perhaps ordered in terms of frequency.
The phoneme detector detects /k/.
The comparator rejects the entries that don’t begin with /bik/ and starts searching the remaining ones, perhaps ordered in terms of frequency.
The phoneme detector detects /ɹ/.
The comparator rejects the entries that don’t begin with /bikɹ/ and starts searching the remaining ones, perhaps ordered in terms of frequency.
Hopefully it finds beaker and signals the process to stop.
There are a few problems with this model. First of all, the constant collection and then rejection of wrong entries seems wasteful. More importantly, there are other factors that influence speed of retrieval, such as whether the target word has been seen recently. Adding such factors to a serial search model tends to make it slow down!
An interactive model of lexical retrieval¶
In the alternative model, information is arranged in layers that interact with one another. I will refer to Fig. 96 to illustrate this process:
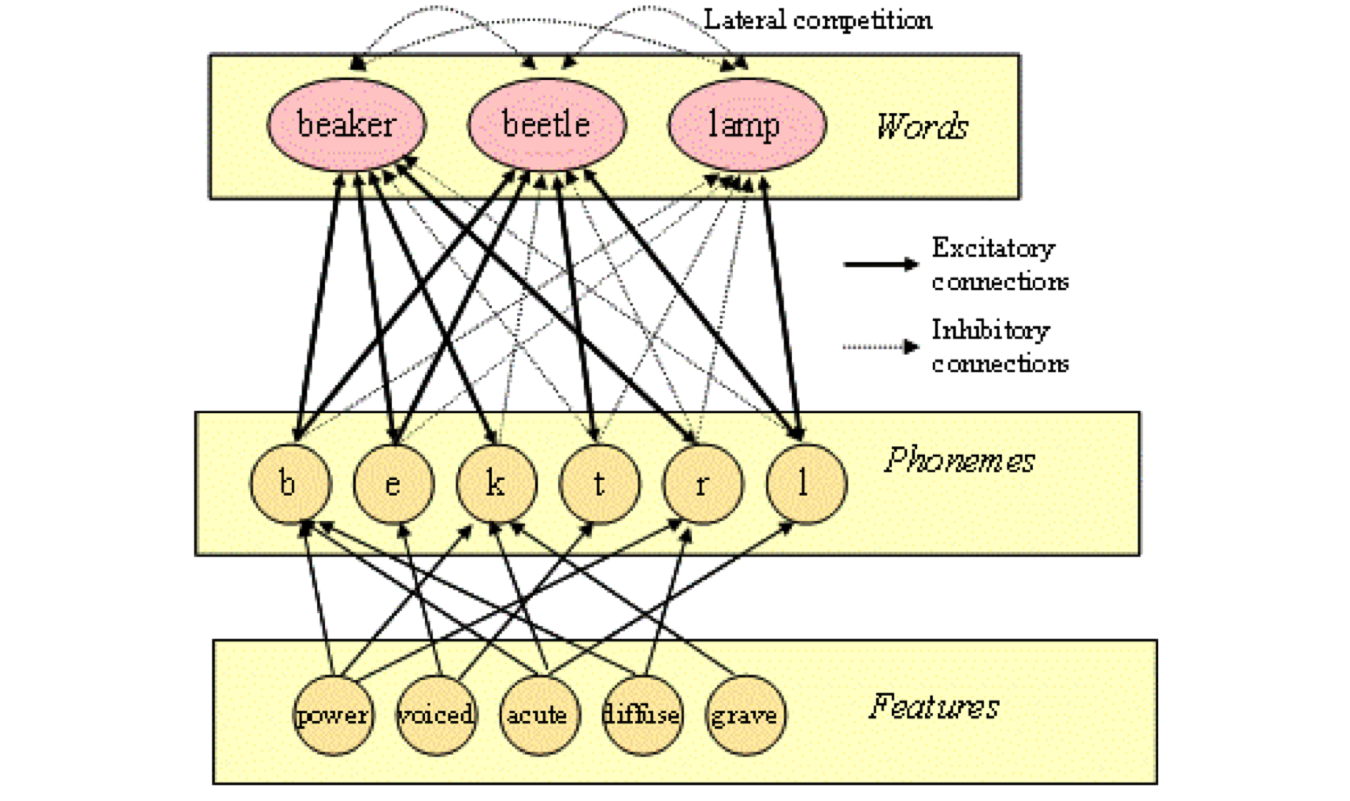
Fig. 96 Interactive model of lexical retrieval (TRACE II).¶
The bottom block of units encodes the various features that are combined to make phonemes. The middle block of units encodes the various phonemes that are concatenated to make words. The top block of units encodes entire words.
There is a flow of activation from the bottom to the top, symbolized by the solid or excitatory arrows. This flow combines smaller units into larger units and so can be understood as the part-of relationship, e.g. b is a part of beaker and bottle. There is a converse flow of information from the top down (but only from words to phonemes) which can be understood as the containment relationship, e.g. beaker contains b. The interaction of these two currents reinforces one another, so that active units such as b and beaker tend to stay active.
This is not enough, however. It is also necessary to link units by inhibition – the dotted arrows – which turns active units off. When all the units in a block are wired together in this manner, it is referred to as lateral inhibition. For instance, each word unit turns its peers off. Thus as activity builds up in beaker, it turns lamp, and eventually beetle, off. There is also block-to-block inhibition from the phonemes to the words, so that an active phoneme inhibits the words that do not contain it, such as b inhibiting lamp.
Excitation tends to highlight the words that contain the phonemes under consideration, while inhibition tends to sweep away the ones that don’t. The interaction between the two conspires to enable the network to choose the correct word in an efficient manner. And as you may imagine, if the network has already seen the target word, some activation may be left hanging around, so that if it sees the word again, it will respond faster, though we will not pursue this possibility here.
In any event, the word layer in Fig. 96 should be in the STS, while the phoneme and feature layers should be in auditory cortex.
Phonological neighborhoods¶
The word layer in Fig. 96 suggests that a word can be said to live in a neighborhood of words that sound like it. In fact, a word can be classified as to how many words sound like it.
Practice
How many different words can you make by changing any of the three sounds that make up badge and log?
Arranging the words that differ by a single change around badge and log and then connecting those words that share a sound produces the following networks:
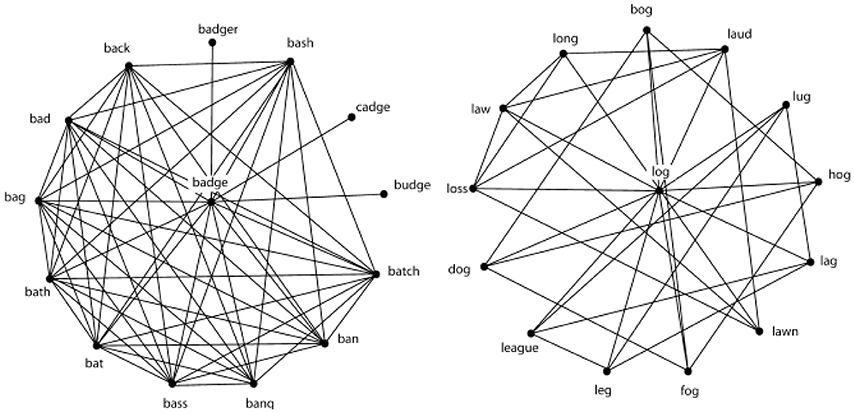
Fig. 97 Network of phonological neighbors of ‘badge’ and of ‘log’.¶
Given this arrangement, badge is characterized as a word with high neighborhood density, while log is characterized as a word with low neighborhood density.
[HP07] summarize a study that contrasts high with low neighborhood density words in the pair of hemispheres below:
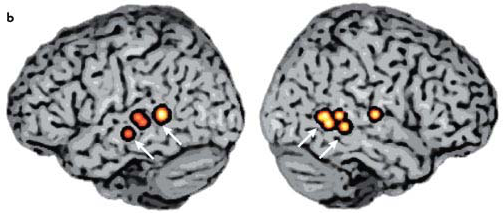
The areas of highest activation lie along the superior temporal sulcus.
Entranement¶
Warning
The following is not incorporated yet.
[ZV16]
We presume that entrainment to low-level features of speech sound occurs relatively early in the auditory pathway (i.e., somewhere between cochlea and primary auditory cortex, including the latter; Davis and Johnsrude, 2003 and Lakatos et al., 2005), whereas entrainment to high-level features occurs beyond primary auditory cortex (Uppenkamp et al., 2006). Important candidates are the supratemporal gyrus (more specifically, mid- and parietal STG) and sulcus (STS), which seem to be primarily involved in the analysis of phonetic features (Binder et al., 2000, DeWitt and Rauschecker, 2012, Hickok and Poeppel, 2007, Mesgarani et al., 2014, Poeppel et al., 2012 and Scott et al., 2000).
Laterality effects¶
Warning
I don’t know of any yet.
Disorders of the STS¶
Agnosia¶
An impairment in the ability to recognize the “meaning” of a stimulus in a specific sensory modality, despite unimpaired perception of the stimulus, is known as agnosia. By “perception” I meant the subcortical processing of the modality, though not everyone shares this interpretation.
Question
What does the “a” of agnosia mean? What about “gnos”?
Auditory agnosia¶
Auditory agnosia is most simply defined as an inability to recognize or differentiate sounds. It was first described by Sigmund Freud in his book on aphasia published in 1891, [Fre91], but the first case of ‘pure’ auditory agnosia (agnosia without aphasia) appears to have been reported only in 1965, cf. [SBF65]. This study describes a patient who was severely impaired at identifying a variety of sounds such as coughing, whistling and a baby crying, but could comprehend speech.
Speech agnosia¶
[Kus77] coined the term pure word deafness to refer to an inability to comprehend spoken words despite intact hearing, speech production and reading ability. Nowadays, this concept has been subsumed under the general heading of agnosia, with the specific title of auditory verbal agnosia or my preference, speech agnosia.
One patient complained that speech sounded “like a great noise all the time … like a gramophone, boom, boom, boom, jumbled together like foreign folks speaking in the distance”. Another said, “I can hear you talking but I can’t translate it”. Here is a typical exchange, quoted from [OG99], p. 45:
Examiner: What did you eat for breakfast?
Patient: Breakfast, breakfast, it sounds familiar but it doesn't speak to me.
The experience of speech appears to undergo a qualitative change, and some speech-agnosic patients cannot judge the length of a word. However, some patients appear able to extract information about the speaker from their voice despite being unable to comprehend the spoken message, such as sex, age, region of origin, or affective information.
[GUR+15] had the rare opportunity to examine a person with bilateral STS lesions but a relatively intact dorsal surface of the superior temporal gyrus. The location of the lesions is highlighted in orange in Bilateral STS lesions producing speech agnosia:
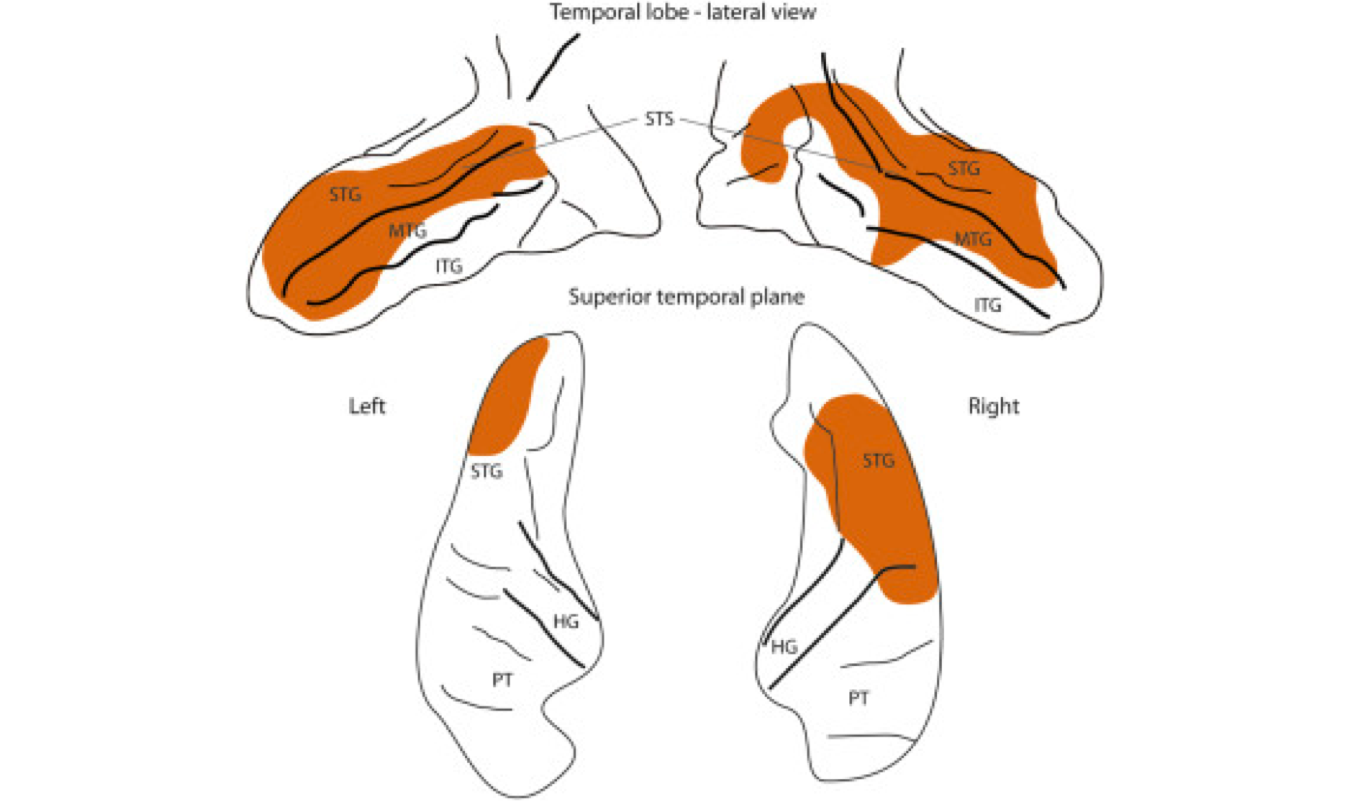
Fig. 101 Bilateral STS lesions producing speech agnosia¶
[GUR+15]. Fig. 2 showing isolated temporal lobe. You should understand STG, MTG & IFG. The “superior temporal plane” is the dorsal surface of the superior temporal gyrus. HG is Heschl’s gyrus or primary auditory cortex, and PT is the planum temporale or Wernicke’s area.
Psychoacoustic tests revealed that the patient had normal hearing, which is to say that his ascending auditory pathway worked properly. EEG of auditory cortex suggested that it was mostly intact, and indeed, he could classify isolated vowels correctly. His writing and speech production were fluent, yet his speech perception was severely deficient.
Bilateral damage to the cortex is exceedingly rare. In my count of the cases reviewed in [Ard17], there have only been seventeen reported since 1877, with [GUR+15]’s being the most recent.
Phonagnosia¶
[AZKB76] describes a group of patients whose ability to recognize familiar voices was severely impaired after damage to the right temporal lobe, though without any disturbance of other auditory tasks. [VLC82] deepened the mystery by pairing a test for voice recognition with one for face recognition. Subjects with RHD or LHD viewed a photograph of a famous person or listened to a recording of a famous voice and then were asked to select the person’s name from a list of four. 5% of the LHD patients failed the test while 44% of the RHD patients failed it, indicating that the identification of both faces and voices takes place in the right hemisphere. [VLCKD88] gathered reports of six patients and found a dissociation between a deficit in recognizing a familiar voice (attendant on damage to inferior and lateral parietal regions of the right hemisphere) and a deficit in discriminating between unfamiliar voices (attendant on damage to the temporal lobe of either hemisphere). [VLCKD88] named this impairment of voice recognition and discrimination phonagnosia.
[RKOvK17] reviews neuroimaging results collected over the intervening years and points out a curious discrepancy. As intimated by [VLCKD88], voice identification seems to be split over the two lobes depicted below:
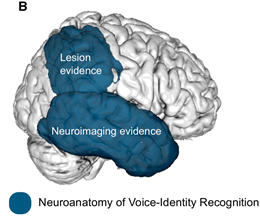
Fig. 102 Potential neuroanatomical representations of voice-identity recognition¶
[RKOvK17], Fig. 1b. “Most lesion studies suggest that the right inferior parietal lobe is critical for voice-identity recognition while neuroimaging studies agree that voice-identity recognition relies on the temporal lobe.”
Question
Which hemisphere is represented in Potential neuroanatomical representations of voice-identity recognition?
[RKOvK17] attempts to resolve this discrepancy with a larger cohort of subjects, more rigorous testing, and up-to-date statistical analysis. They summarize their results in this image:
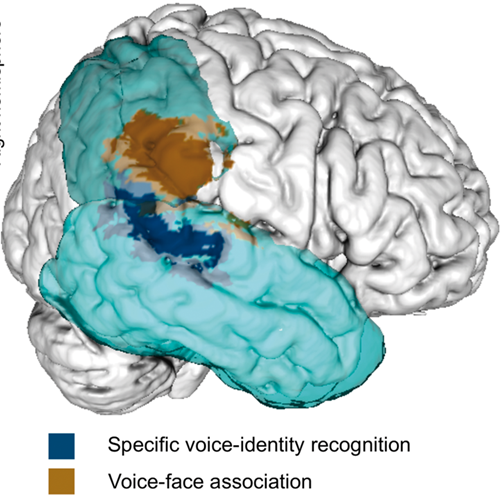
Fig. 103 Lesions associated with decreased voice-identity recognition¶
[RKOvK17], Fig 5.
Question
What is your reaction to this image? What do you know about the ‘end’ of the superior temporal sulcus, which appears to overlap with the cyan portion of the image?
In [RKOvK17]’s own words:
[Our findings] support the central assumption that the right posterior/mid temporal lobe is crucially involved in voice-identity recognition alone and not to the same extent in face-identity recognition or speech processing. However, they also uncover two novel aspects of voice-identity recognition that are not yet included in current models: (i) the critical involvement of the right inferior parietal lobe, particularly the supramarginal gyrus, in voice-identity recognition tasks requiring voice-face association; and (ii) a potential partial dissociation of identity recognition for voices with varying levels of familiarity.
Age, sex, size, emotional state, geographical and sociological background-all these attributes contribute to the specification of the acoustic signal to produce the individual’s unique speech pattern
Summary¶
Name |
Non-speech sounds |
Voices |
Speech |
Cause |
|---|---|---|---|---|
Cortical deafness |
❌ |
❌ |
❌ |
damage to bilateral A1/core |
Auditory agnosia |
❌ |
✓ |
✓ |
damage to feature detectors in A2 & A3 |
Speech agnosia |
✓ |
✓ |
❌ |
damage to detectors specific to speech in bilateral STS |
Phonagnosia |
✓ |
❌ |
✓ |
damage to detectors specific to voice identity in right Wernicke’s area/planum temporale |
Analogous visual agnosias¶
Vision gives rise to analogous agnosias. An inability to recognize visual objects in general is called visual agnosia. A disruption in the ability to recognize written words is termed alexia or word blindness. An impairment in the ability to recognize (familiar) faces is known as prosopagnosia, which has a double dissociation between memory for familiar faces and discrimination of unfamiliar faces.
Description |
Audition |
Vision |
|---|---|---|
Can not recognize objects in general |
auditory agnosia |
visual agnosia |
Can not recognize linguistic objects |
speech agnosia (verbal auditory agnosia, pure word deafness) |
alexia (word blindness) |
Can not recognize human objects |
phonagnosia |
prosopagnosia (face blindness) |
End notes¶
The next topic¶
The next topic is Wernicke’s aphasia.
Last edited Aug 18, 2025
Social perception along the STS¶
[Bea15] reviews five phenomena which take place along the superior temporal sulcus that can be brought together under the banner of social perception, as summarized in this mapping onto the two hemispheres:
Fig. 99 Social perception along the STS. [4]¶
We will review these five areas, from anterior to posterior.
Perception of language¶
Perception of the human voice¶
The McGurk effect¶
As reported in [MM76], Harry McGurk and his research assistant, John MacDonald, asked a technician to dub a video with a different phone from the one spoken while conducting a study on how infants perceive language at different developmental stages. When the video was played back, both researchers heard a third phone rather than the one spoken or mouthed in the video. As an example, the syllable [ba.ba] is dubbed over the lip movements of [ga.ga], and the perception is of [da.da].
Voice as face: person recognition¶
Moving faces¶
Biological motion¶
See the video Johansson experiment on YouTube.
Mentalizing or theory of mind¶
Fig. 100 Jon and Garfield think about pizza¶
Adapted from No. 1463: Garfield Minus Theory of Mind. Strip from 1992-11-21.