Speech¶
Introduction¶
Up to now, we have assumed that all frequencies are equal. In this chapter, I finally single out speech as being the most equal, though I may refer to music every now and then.
One of the goals of this chapter is for you to become familiar with acoustic representations, such as that of a recording of me pronouncing the vowels [ieaou]. I open it in Praat to Fig. 14:
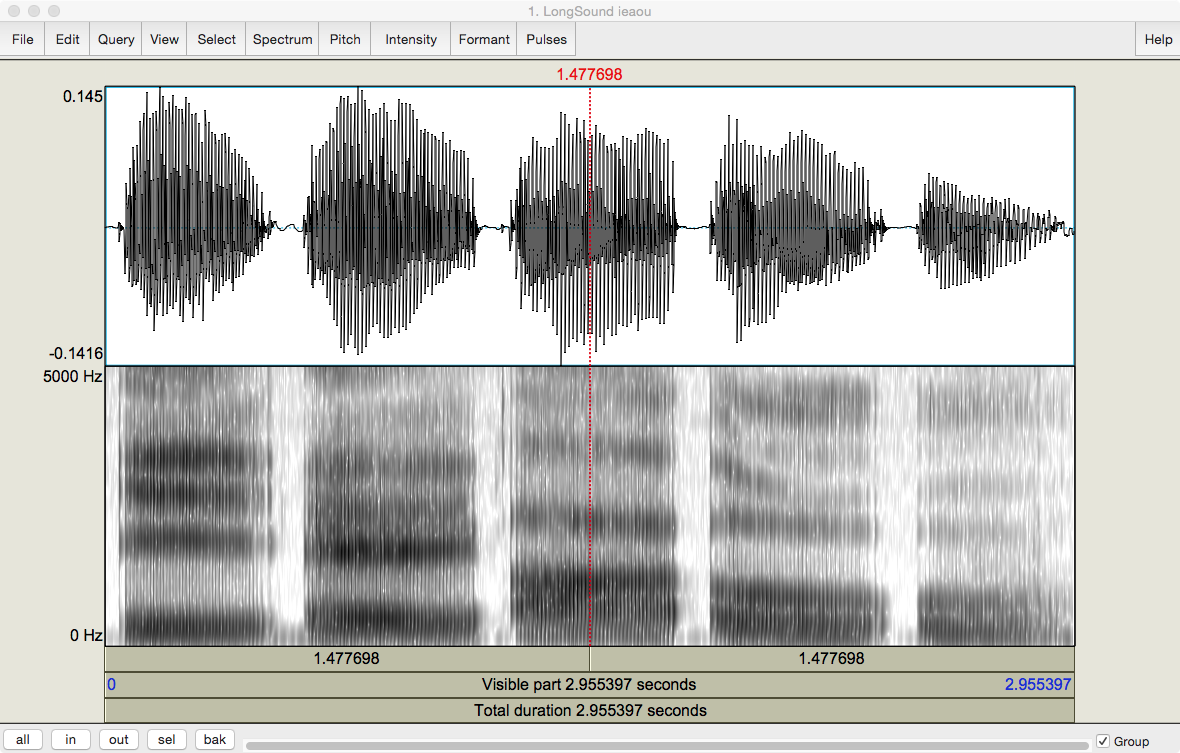
Fig. 14 The author’s pronunciation of [ieaou].¶
Screenshot from Praat.
Questions
Praat has set the cursor (red line) at the middle of the recording by default. How long is each half?
I tried to articulate each vowel for the same length of time. How long is this?
Why does the last vowel in the top graph look different from the others?
You should be able to figure out most of the answers. I’ll give you a hand with the third. The last vowel has a lesser ‘footprint’ because we tend to reduce our speech towards the end of an utterance, presumably to save effort. Thus the amplitude tracing at the top gradually shrinks, while the frequency trace underneath gets gradually fainter.
Segmental vs supra-segmental analysis¶
Phonetics (and phonology) makes an initial distinction between those aspects of speech that tend to be captured by an alphabet and those that are captured by punctuation, called segmental and supra-segmental or prosodic acoustic phonetics, respectively. A segment is the basic unit of phonetic analysis. Each segment in a language can by written by a symbol drawn from the International Phonetic Alphabet.
Articulatory phonetics: like having a guitar in your throat¶
So how do the vowels in Fig. 14 come to be? They come from my favorite sound-production device, the human voice. At the largest scale, it is composed of the three parts in Fig. 15:
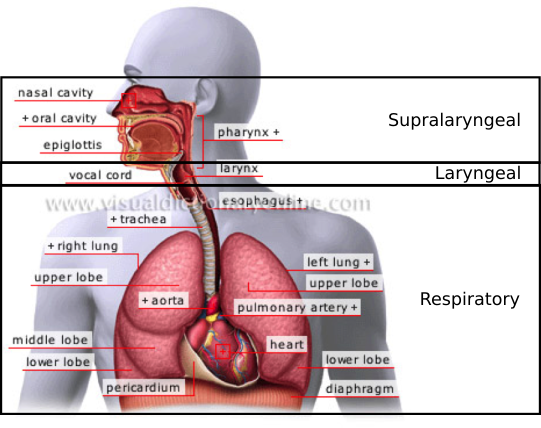
Fig. 15 Three systems involved in speech production¶
{kind=link}
The respiratory system produces a column of air that makes the vocal cords vibrate in the laryngeal system which is filtered by the supralaryngeal system to produce the sounds that we recognize as speech.
The laryngeal system¶
The air pushed up the trachea by the lungs does not in itself have any interesting linguistic properties, but once it passes through the vocal cords or folds, it certainly does. If you cut off my head and looked straight down my trachea, you would see something like Fig. 16:
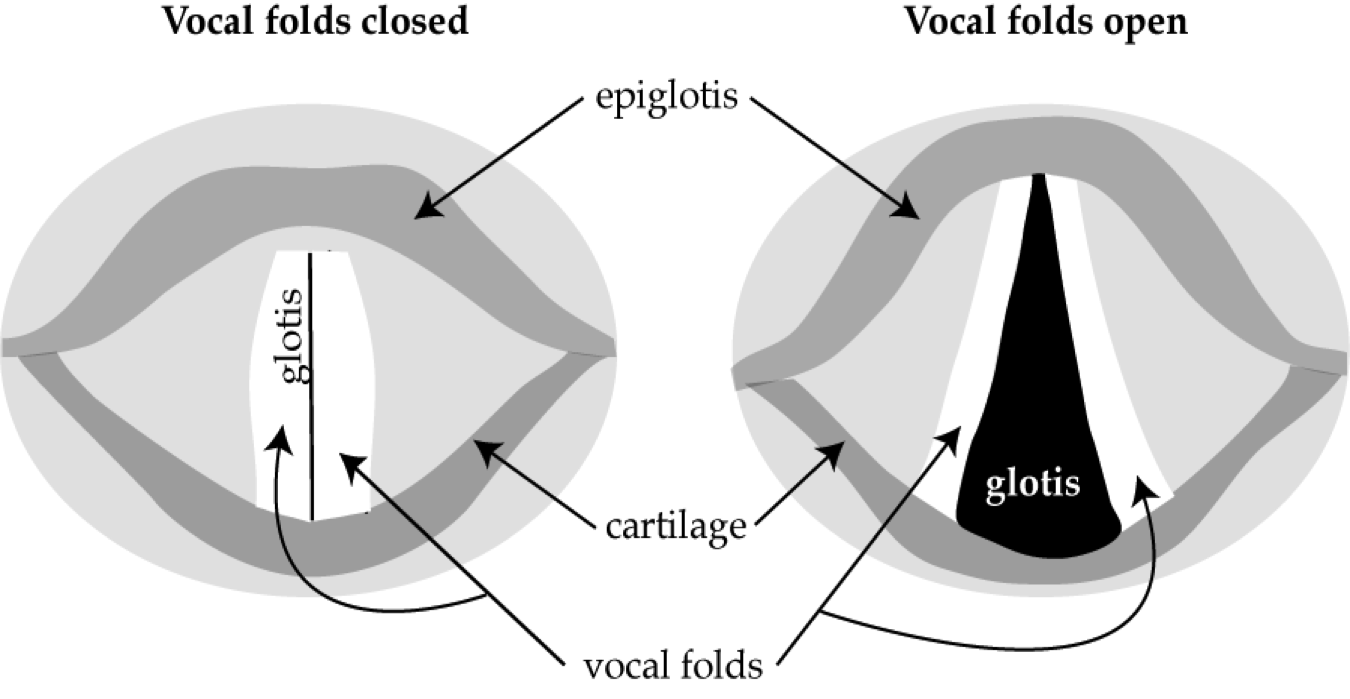
Fig. 16 Vocal cords¶
Author’s image
When the vocal folds are closed, as in the left side of the image, no expiratory airflow can enter the supralaryngeal system, so there is silence, and expiratory air is compressed, raising its pressure. When the vocal folds are open, as in the right side of the image, an opening appears called the glottis which allows expiratory airflow to enter the supralaryngeal system and create speech sounds, or phonation, and expiratory airflow is decompressed or rarefied and its pressure falls.
The vocal folds are more of a mucous membrane than a muscle and so tend to snap back to their closed position after being open. Their opening and closing compresses and releases the expiratory airflow as in Fig. 17, producing a cycle which you should now be familiar with:
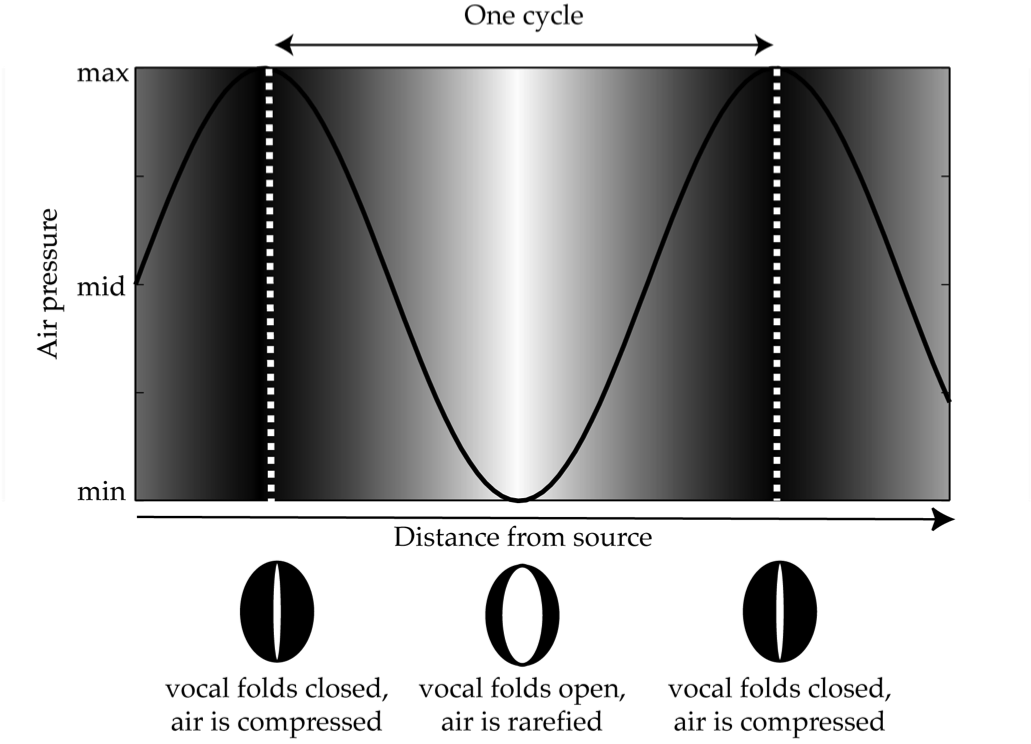
Fig. 17 Graph of turbulent oscillation of vocal air¶
Author’s image.
Increasing darkness symbolizes increasing compression of the airflow. The vertical scale represents the pressure of the airflow through the vocal folds as a single quantity between a minimum and a maximum. A single cycle of closing and opening is defined by the distance between two peaks, marked by dotted white lines.
The outcome is that the each vocal fold vibrates periodically, like a guitar string. And like in Fig. 10, the image above illustrates the fundamental frequency of the vocal folds.
Modern recording technology is fast enough to catch the vocal folds in action. The image below zooms in on the beginning of the first vowel in Fig. 14:
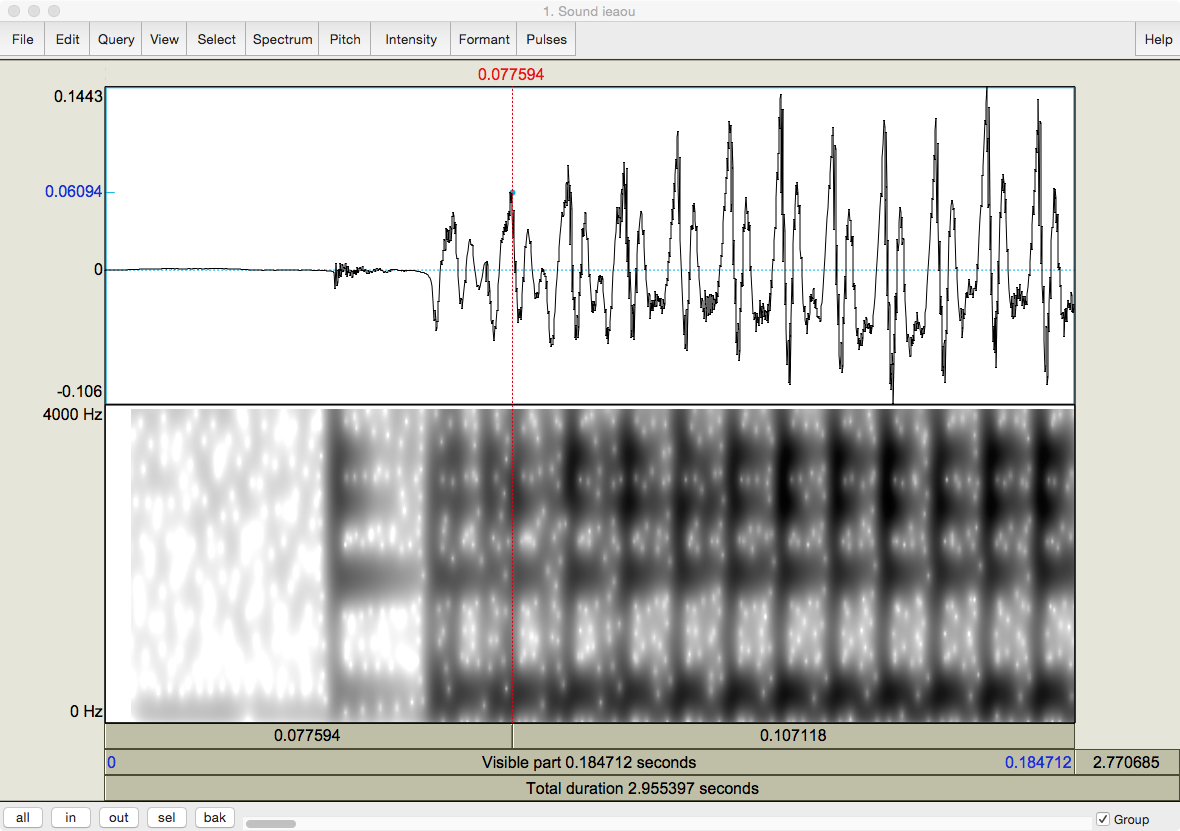
Fig. 18 Close-up of the beginning of the first vowel in Fig. 14.¶
Screen capture from Praat.
Question
How much of the original recording does this one capture?
The peak of each pressure wave corresponds with the darkest band of the frequency spectrum, as I tried to point out by placing the cursor over one.
Fundamental frequency¶
Recall from the discussion of a vibrating guitar string that the vibration of the entire string is known as its fundamental frequency. If you know the length of a string you can calculate its fundamental frequency … well almost, you also need to know how fast the waves produced by the string can travel. This is the speed of sound, which at 20° C is 343 meter/second. [1] The calculation proceeds as in (1), where the length of the string is given by L and the velocity of air, v:
Vocal cords work just like strings.
Fundamental frequency and sex
The fundamental frequency of a man’s voice averages 125 Hz; that of a woman’s voice averages 200 Hz.
What does that tell you about the length of their respective vocal cords?
The fundamental frequency is what gives a voice its characteristic pitch. According to Benward’s and Saker’s Music: In Theory and Practice:
Since the fundamental is the lowest frequency and is also perceived as the loudest, the ear identifies it as the specific pitch of the musical tone [or voice, HH] … The individual partials are not heard separately but are blended together by the ear into a single tone.
Praat can display the fundamental frequency, as in this rehash of Fig. 14:
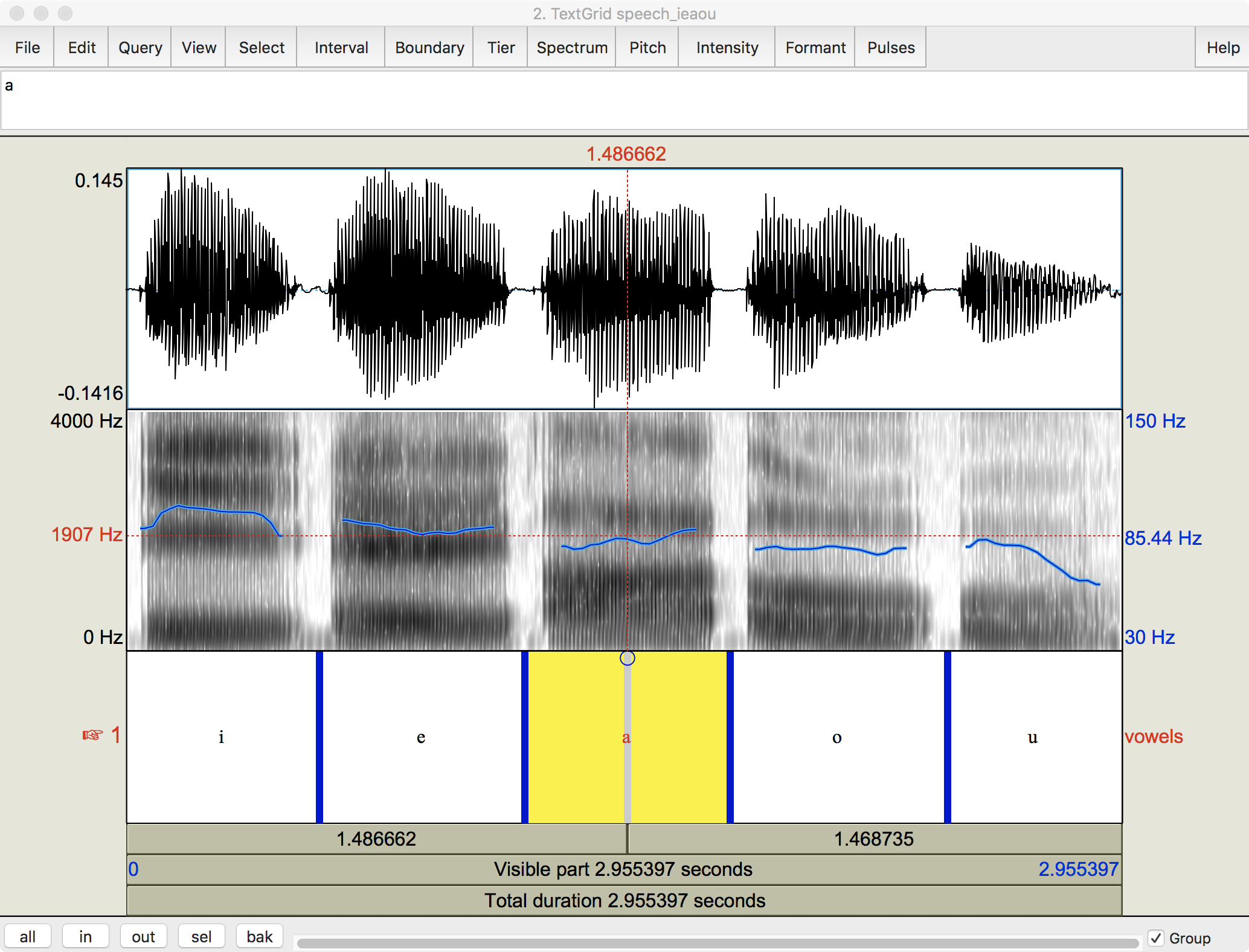
Fig. 19 Five vowels with fundamental frequency¶
Author’s screenshot from Praat
Question
So what’s different?
There is a third y axis displayed in blue on the right side. It is measured in Hertz, but with the very narrow range of 30 - 150 Hz. I eye-balled the cursor at about the middle of my range, 85 Hz. Assuming that is really the average for me …
Question
What does that tell you about my voice with respect to that of the ‘average’ man mentioned above?
Finally, a technical question.
Question
Why does Praat add an entirely new scale for the fundamental frequency instead of just putting it with the other frequencies?
The supralaryngeal system¶
But just like a plucked guitar string, the vocal folds vibrate at a variety of frequencies that are multiples of the fundamental. If we could hear just this pulse, it would sound, as Loritz (1999:93) says, “more like a quick, dull thud than a ringing bell”.
Yet the human voice does not sound like a quick, dull thud; it sounds, well, it sounds like a human voice. This is because the supralaryngeal system sits on top of the larynx and filters the glottal pulse just like different fingerings of a guitar string filters its vibrations:
Fig. 20 A close-up of the supralaryngeal system, along with the laryngeal system.¶
Author’s image.
In particular, the oral and nasal cavities resonate at certain frequencies, thereby exaggerating some harmonics while muting others.
Vowels¶
For a vowel, the mouth reaches its maximum opening.
Question
How many vowels are there in (American) English?
If you said five, i.e. ‘i, e, a, o, u’, I invite you pronounce the following words:
‘beat, bit, bait, bet, bat, but, cot, bought, boat, book, boot’
Now how many vowels do you think there are in (American) English?
Eleven is a much better answer than five. But of course, the English alphabet only has symbols for five of them, so to represent the others consistently, we will have to draw on a broader inventory. This is the purpose of the International Phonetic Alphabet.
Before seeing the additional symbols, let me say a few words about how vowels are described.
Task
Put your hand under your jaw and say the vowel of ‘beat, bit, bait, bet, bat, cot’. What does your jaw do?
Now try the sequence in reverse. Put your hand under your jaw and say the vowel of ‘cot, bat, bet, bait, bit, beat’. What does your jaw do?
For the first sequence, you should feel your jaw going down. This is because your mouth is opening to allow your tongue to go down. Conversely, for the first sequence, you should feel your jaw going up. This is because your mouth is closing to allow your tongue to go down.
The parallel motion happens for the second half of the set of English vowels:
Task
Put your hand under your jaw and say the vowel of ‘boot, book, boat, bought, cot’. What does your jaw do?
Now try the sequence in reverse. Put your hand under your jaw and say the vowel of ‘cot, bought, boat, book, boot’. What does your jaw do?
As before, your jaw goes down, then up, because your tongue goes down, then up.
The result is that vowels can be classified by height (of the tongue). The vowel of ‘cot’ is the lowest, and the vowels of ‘beat’ and ‘boot’ are the highest, with the rest falling in between.
There is a perpendicular motion of the tongue, too – tongue advancement – but you can’t feel it the way you can feel your jaw move. The vowel of ‘beat’ occupies the front-most position, while the vowel of ‘boot’ occupies the rear-most position. This leads to the following cross-classification:
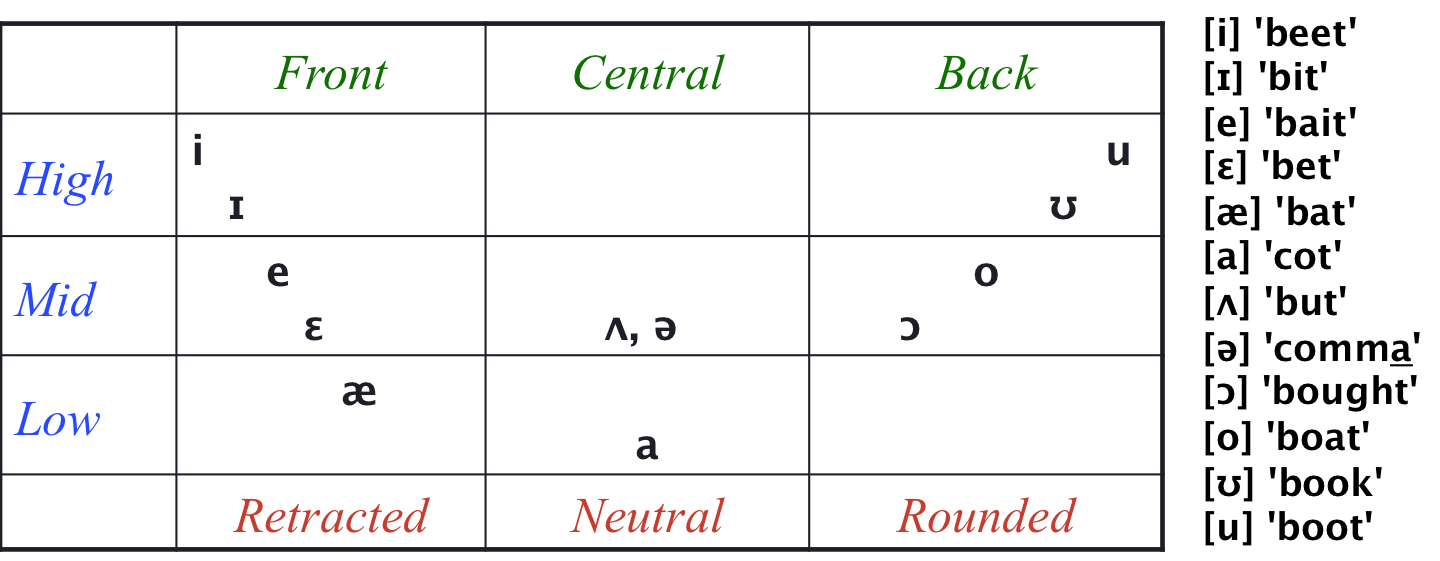
Fig. 21 The vowel triangle of American English.¶
Author’s image.
The only bit that may need some additional explanation is the difference between [ʌ] “caret” and [ə] “schwa”. The former is the choice for stressed syllables and the latter for unstressed ones, such as the last syllable of ‘comma’, though I think that the two sound identical.
 For a detailed overview of how difficult it is to describe English vowels, see the Vowel heading of Wikipedia’s English phonology page.
For a detailed overview of how difficult it is to describe English vowels, see the Vowel heading of Wikipedia’s English phonology page.
As for the full IPA chart of vowels, Wikipedia has a nice rendition with sample pronunciations at IPA vowel chart with audio.
With a little bit of imagination, you can see the vowels arrayed in a triangular fashion in Fig. 21, with the three points at [i], [a], and [u].
Question
All languages have at least [i, a, u]. Can you think of a reason why?
There is one vowel descriptor that I have skipped over.
Question
Say [u]. What are your lips doing? Now say [i]. Do your lips stay in the same position? How does [a] compare to the other two?
The bottom line of Fig. 21 summarizes the shape of the lips. For the articulation of a back vowel, the lips are rounded, which you can easily feel. A front vowel is articulated in the opposite manner, with the corners of the mouth drawn away so that the lips take on a slit-like shape, labeled “retracted”. A central vowel is articulated in between the two extremes, with a neutral shape.
Given how easy it is for you to feel what your lips are doing, lip shape would be a much more intuitive property of vowels than tongue advancement. Unfortunately, the tradition in phonetics relies on tongue advancement. Moreover, in English, lip shape can be predicted from tongue advancement – just read down from tongue advancement to find lip shape – so it adds no new information. Lip shape is therefore redundant, and I won’t have much to say about it in the upcoming text.
Lip shape is not redundant in all languages, though.
Task
Say [i] and round your lips for [u] at the same time. Do you know this vowel? Likewise, say [e] and round your lips for [o]. How about this one?
The following two images illustrate how position in the vowel triangle translates into different configurations of buccal cavities:

Fig. 22 The three buccal cavities articulating [i] and [a].¶
Author’s image.
The oral cavity itself sits in a channel between two smaller cavities whose size varies according to the position of the tongue and lips. Counting from the back, there is:
a pharyngeal cavity,
an oral cavity properly speaking, and
a labiodental cavity, between the teeth and the lips.
Notice how the difference in tongue position for [i] and [a] changes the size of the oral and pharyngeal cavities. For [i], the tongue is high and forward, shrinking the oral cavity while expanding the pharyngeal one. For [a], the tongue is low and centered, expanding the the oral cavity greatly while shrinking the pharyngeal one. In the next section, you will learn how such cavity shapes produce particular constellations of frequency.
But let’s fix in your mind the arbitrary nature of English spelling by transcribing a few vowels to IPA.
Practice. Indicate the IPA symbol for the vowel in the following words
|
|
|
Here is a spectrogram of my pronunciation of the vowels [i, a]:
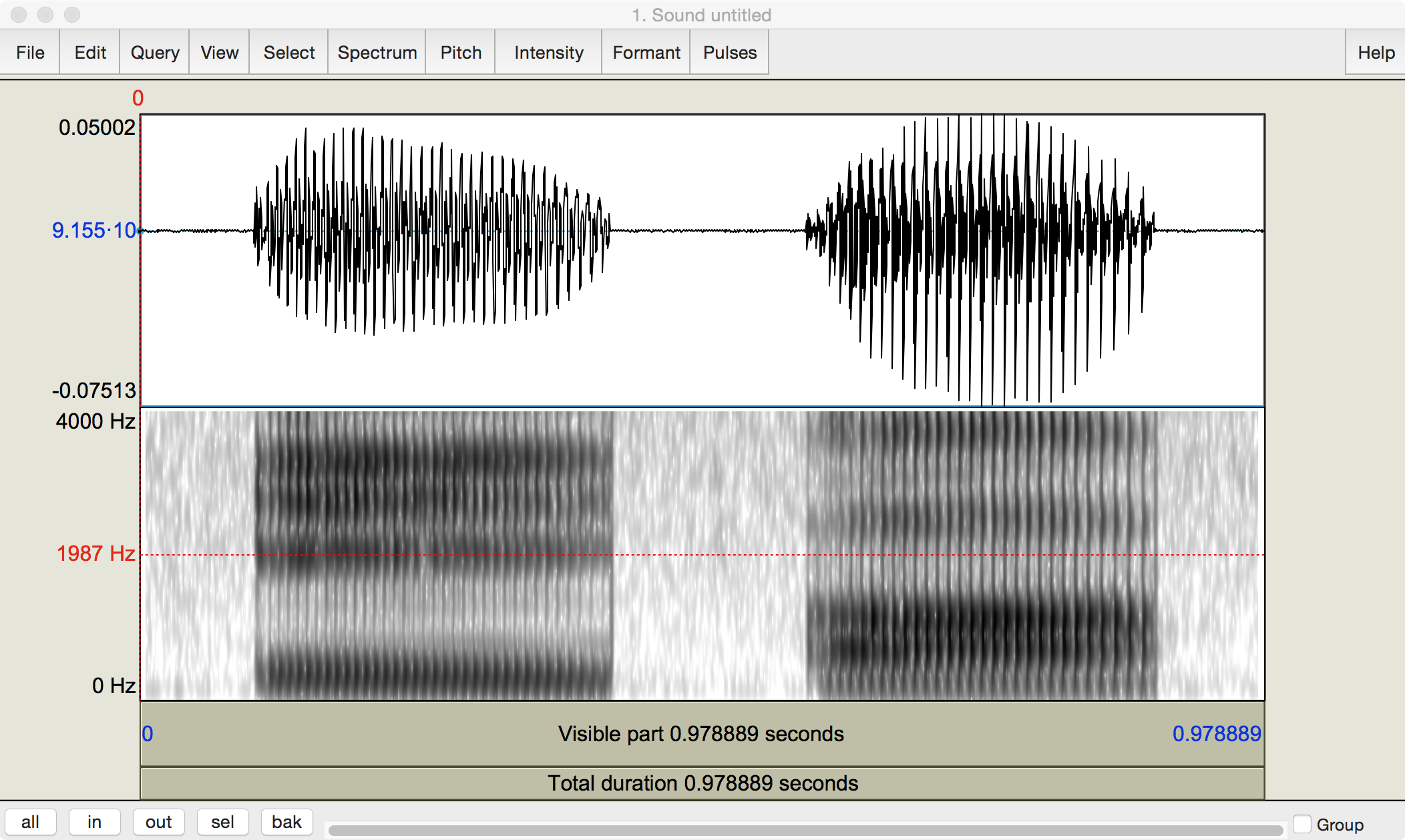
Fig. 23 Pressure and wide-band spectrogram of author’s [i, a].¶
Author’s screen capture from Praat.
The frequency tracing at the bottom is marked by distinctive horizontal bands, called formants. They are named by counting them from the bottom up. In theory, the initial one is the fundamental frequency, \(F_0\), but it is too low to be readable in such a broad range of frequencies. The next one, the first formant \(F_1\) is the lowest for both vowels but is at different heights. They continue upwards, but it is usually just the bottom two that are most informative. This image picks them out for you:
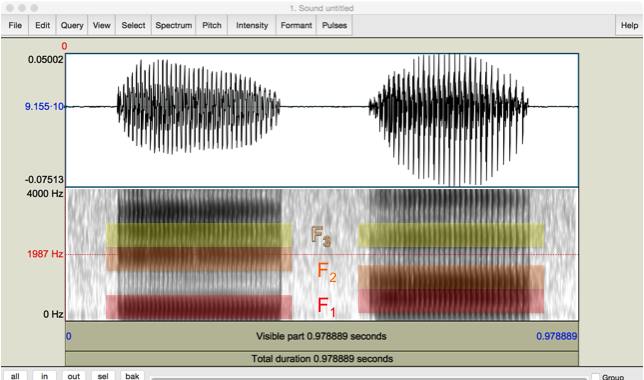
Fig. 24 Pressure and wide-band spectrogram of author’s [i, a] with first three formants colored.¶
Author’s screen capture from Praat.
Question
What do the colors mean?
Rob Hagiwara has a wonderful series of spectrograms of the non-schwa English vowels, over which I have superimposed colored bars to highlight how the formants rise or fall with vowel quality:
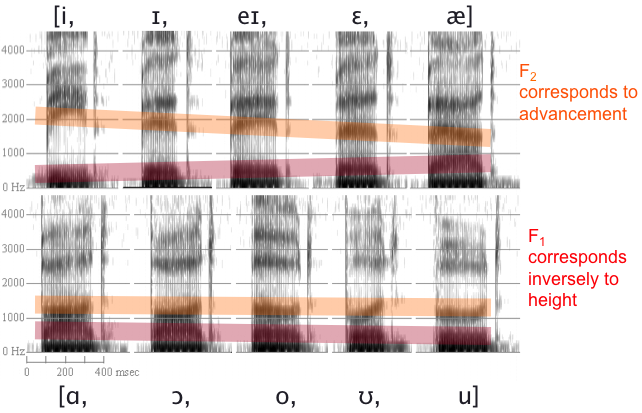
Fig. 25 Wide-band spectrogram of English vowels in [b__d].¶
In the red bars, you should be able to discern that as \(F_1\) rises, tongue height falls. That is, the higher \(F_1\), the lower the vowel is in The vowel triangle of American English.. Thus \(F_1\) is inversely correlated to vowel height. As for the orange bars, you should be able to make out that as \(F_2\) rises, tongue advancement increases. Which is to say that, the higher \(F_2\), the further forward the vowel is in The vowel triangle of American English.. Thus \(F_1\) is (directly) correlated to tongue advancement.
Questions
Should [i] have the largest value for \(F_1\) or \(F_2\)?
Should [i] and [u] have the smallest values for \(F_1\) or \(F_2\)?
Should [a] have the smallest or greatest value for \(F_1\)?
Consonants¶
Have I defined what a vowel is? Well, imagine that you spoke like this:
Source: http://soundbible.com/ 1188-Chimpanzee by Mike Koenig.
Question
Does this sound like a vowel to you?
As you will see below, it certainly looks like a vowel, repeated three times. So imagine that you could only speak in vowels. How many messages could you convey? Unless you start mixing vowels, only about eleven. And even if you did mix vowels to make different messages, the transitions between vowels would be hard to perceive.
Humans have solved this problem by creating a whole new category of articulations, called consonants, which close the mouth around a vowel. Thus we propose the definitions of a vowel as an articulation in which the mouth is maximally open, in contrast to a consonant, which closes the mouth, partially or completely.
Consonants are distinguished by three characteristics, which you will figure out with a little prodding from me.
Task. Pronounce the consonant at the beginning of these words
‘paw, fee, thigh, sea, shy, key, hay’
Except for the last two, you should be able to feel distinctly what your mouth is doing.
In sequence, the articulators and the phonetic term used to describe them are:
example |
articulators |
term |
|---|---|---|
[p] |
both lips |
bilabial |
[f] |
the bottom teeth and top lip |
labiodental |
[θ] |
between the teeth |
interdental |
[s] |
the alveolar ridge on the gums right above the top teeth |
alveolar |
[ʃ] |
the hard palate or roof of the mouth, where peanut butter sticks |
palatal |
[k] |
the soft palate |
velar |
[h] |
the back of the mouth behind the tongue |
glottal |
This characteristic of consonants is known as place of articulation.
You can figure out the second characteristic of consonants by …
Task. Pronounce the consonant at the beginning of these words
‘paw, moo, Joe, Lou/roux, so, yo’
Again, you should have clear intuitions about what your mouth does. The following table puts them into prose:
example |
articulators |
term |
|---|---|---|
[p] |
the expiratory airflow is momentarily halted |
stop |
[m] |
the mouth is closed but the expiratory airflow is diverted through the nose |
nasal |
[ʤ] |
the expiratory airflow pauses but then resumes with turbulence |
affricate |
[l, ɹ] |
the expiratory airflow exits through one side of the mouth or over the curled tongue |
liquid: lateral or rhotic |
[s] |
the expiratory airflow exits with turbulence |
palatal |
[j] |
the mouth is open enough that the expiratory airflow approximates a vowel |
glide or semiconsonant |
This characteristic of consonants is known as their manner of articulation.
The third and final characteristic of consonants becomes apparent by contrasting pairs …
Task. Place the palm of your hand on your throat and pronounce the consonant at the beginning of these words. Do you notice a vibration or not?
‘fee/bee, thin/then, sue/zoo, bash/badge, hey’
In the first member of each pair, plus ‘hey’, you should feel nothing in your throat, while in the second you should feel a distinct buzzing. This is called voicing. A consonant that lacks it is unvoiced or voiceless; a consonant that has it is voiced.
The three features cross-classify the consonants as depicted in this table:
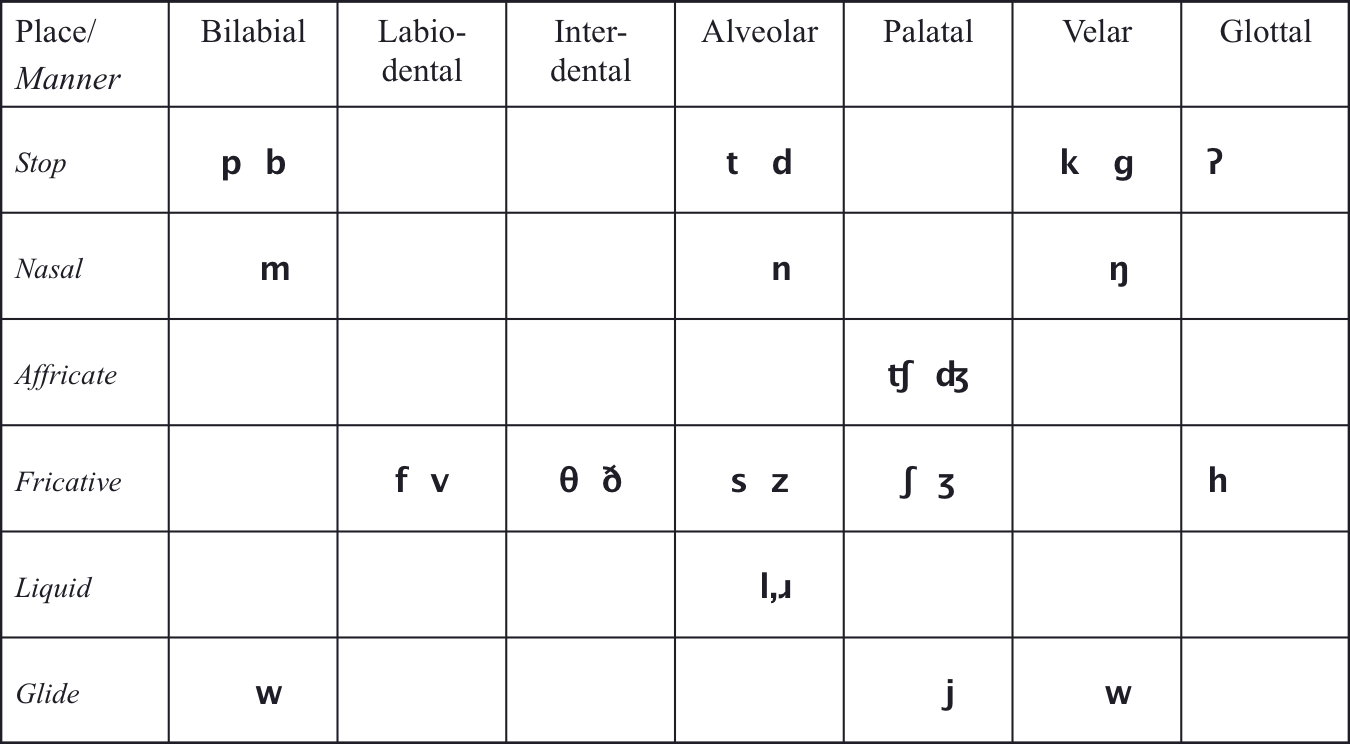
Fig. 26 English consonants, paired as voiceless ~ voiced.¶
Author’s image.
Here are some examples of the symbols that you may not be familiar with:
symbol |
example |
|---|---|
[ʔ] |
Uh-oh! |
[ŋ] |
Ang |
[ʧ] |
chew |
[ʤ] |
Joe |
[θ] |
thigh |
[ð] |
thy |
[ʃ] |
shy |
[ʒ] |
edge |
One closing comment is in order. [w] is listed twice because it has two closures, a bilabial one and a velar one. It is known as a labiovelar, which doesn’t fit comfortably into the table.
Question
What is the voicing of the nasals, liquids, and glides?
Let’s continue fixing in your mind the arbitrary nature of English spelling by forcing you to focus on the actual pronunciation of a handful of words.
Practice. Transcribe the following words into the IPA.
|
|
|
A consonant can be identified by its three features, usually in the sequence “voicing manner place”. For instance, [b] is a voiceless bilabial stop, while [ʤ] is a voiced palatal affricate.
Practice. Identify the following symbols by their features
|
|
|
From these articulatory characteristics of the mouth, we can jump to their acoustic consequences, to get you started with actually understanding how the brain looks at speech.
The acoustic repercussions of consonant closures are varied.
Most consonants must be articulated along with a vowel. The image below analyzes [ɑbɑdɑgɑ], from the files :
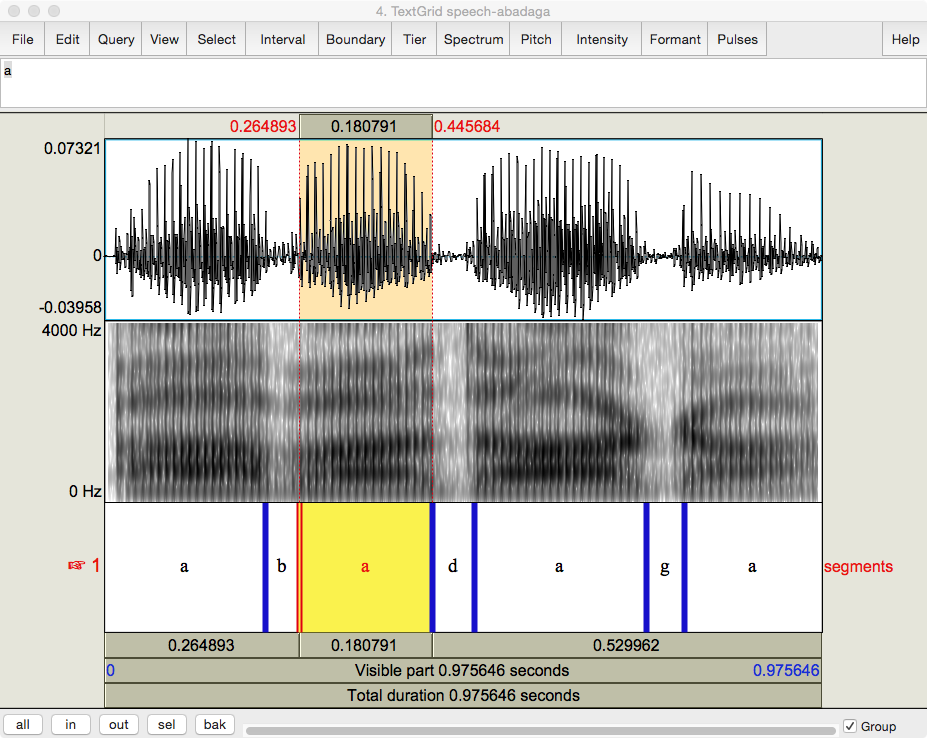
Fig. 27 Pressure and wide-band spectrogram of author’s [ɑbɑdɑgɑ]¶
Author’s screen capture from Praat.
Question
Looking just at the two waveforms and knowing that a consonant is a constriction of the airflow, where do you think [b, d, g] are?
Underneath the spectrogram, Praat opens up a tier for me to label the waveform. I divided it into its segments and left the second [a] selected. The constriction for the three voiced stops is where the pressure drops abruptly and the spectrogram goes cloudy. My closure on [b] was not very crisp – you can see how the vowel almost continues straight through it, but I succeeded a bit better on [d] and [g] – especially [d], which clearly interrupts the acoustic signature of the surrounding vowels.
Turning to the fricatives, the image below displays [fθsʃh], from the files :
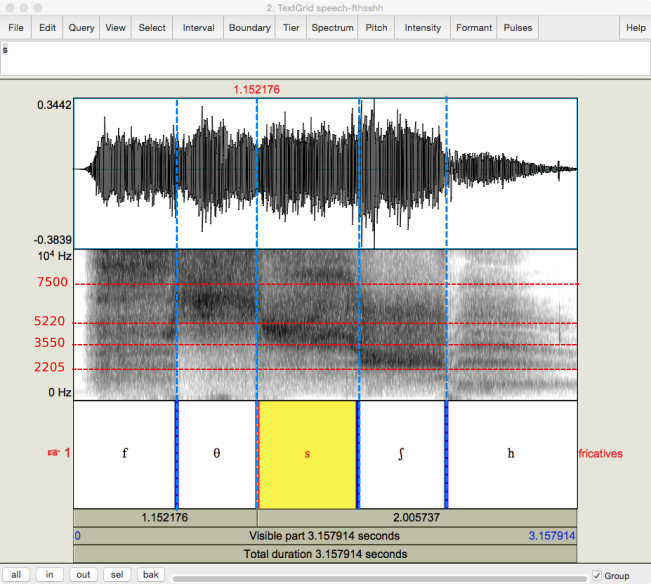
Fig. 28 Pressure and wide-band spectrogram of author’s voiceless fricatives [fθsʃh].¶
Author’s screen capture from Praat.
Question
What is the range of frequencies?
While I have maintained that fricatives sound like wind – or random frequencies – and so can’t bear any information, not all random bunches of frequencies are created equal. [ʃ] has a band of energy starting at about 2205 Hz, [s] has one at about 3550 Hz and [θ] has one at about 5220 Hz. [f] might have one in the vicinity of 7500 Hz, it’s hard to tell. In contrast, [h] appears to have no energy at all, though it does suggest a ghostly background of formants. Looking at it from front to back, fricative energy appears to step downwards as the place of articulation moves back. [h] is said to have no constriction at all, so it is just air passing through the mouth and may reflect the basic architecture of the vocal tract.
Spectral vs. temporal information¶
The notion of spectrum can be generalized to the continuum of frequencies of sound, and in particular to those of speech. The figure below superimposes the spectrum of the rainbow onto the first four formants of “BP”:
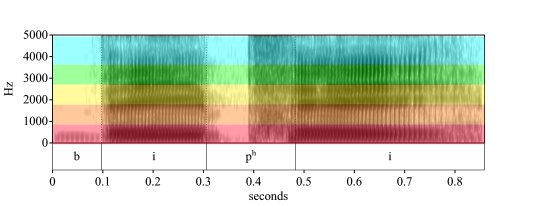
Fig. 29 “BP”, overlaid with a color spectrum ordered congruently by wavelength¶
Author’s image from Praat.
The spectral information is fundamental to identifying the sounds in Fig. 29, but the temporal information should not be overlooked. The vowels are much longer than the consonants, while the transitions between them are fairly crisp, usually taking only between two and four vibrations of the vocal folds. Fig. 30 overlays the previous spectrogram with long and short windows of time that highlight representative steady-state frequencies of the vowels and several frequency transitions:
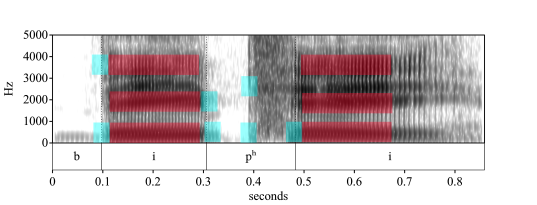
Fig. 30 “BP”, overlaid with two temporal windows.¶
Author’s image from Praat.
Question
Why is the long window red and the short window blue?
The long window measures about 180 ms, while the short one measures about 30 ms. Dividing 1000 ms by each one, 1000/180 and 1000/30 rounds out to 6 and 33 Hz, respectively. That is to say, six red windows and thirty-three blue windows fit into a second, so each window can be understood as a cycle and thus be measured in Hertz, as a frequency. As a low-frequency entity, the long window is labelled red; conversely, as a high(er)-frequency entity, the short window is labelled blue.
Supra-segmental or prosodic acoustic phonetics¶
Prosody is the quality of spoken language that provides its melodic contour and rhythm, features which help the hearer to decode syntactic and lexical meaning as well as emotional content. Prosody differentiates, say, the neutral statement of fact “It’s my fault” from the sarcastic question-like rejoinder “It’s MY fault?”.
Such distinctions are produced by variation in three parameters, which are borne in turn by three qualities of sound waves, respectively:
Sound waves |
Prosody |
|---|---|
fundamental frequency |
pitch |
intensity |
stress |
timing |
duration |
Question
Which one of these parameters should already be able to elaborate a hypothesis for?
I invite you to contemplate the graph of three quantities in Fig. 31, measured from its source:
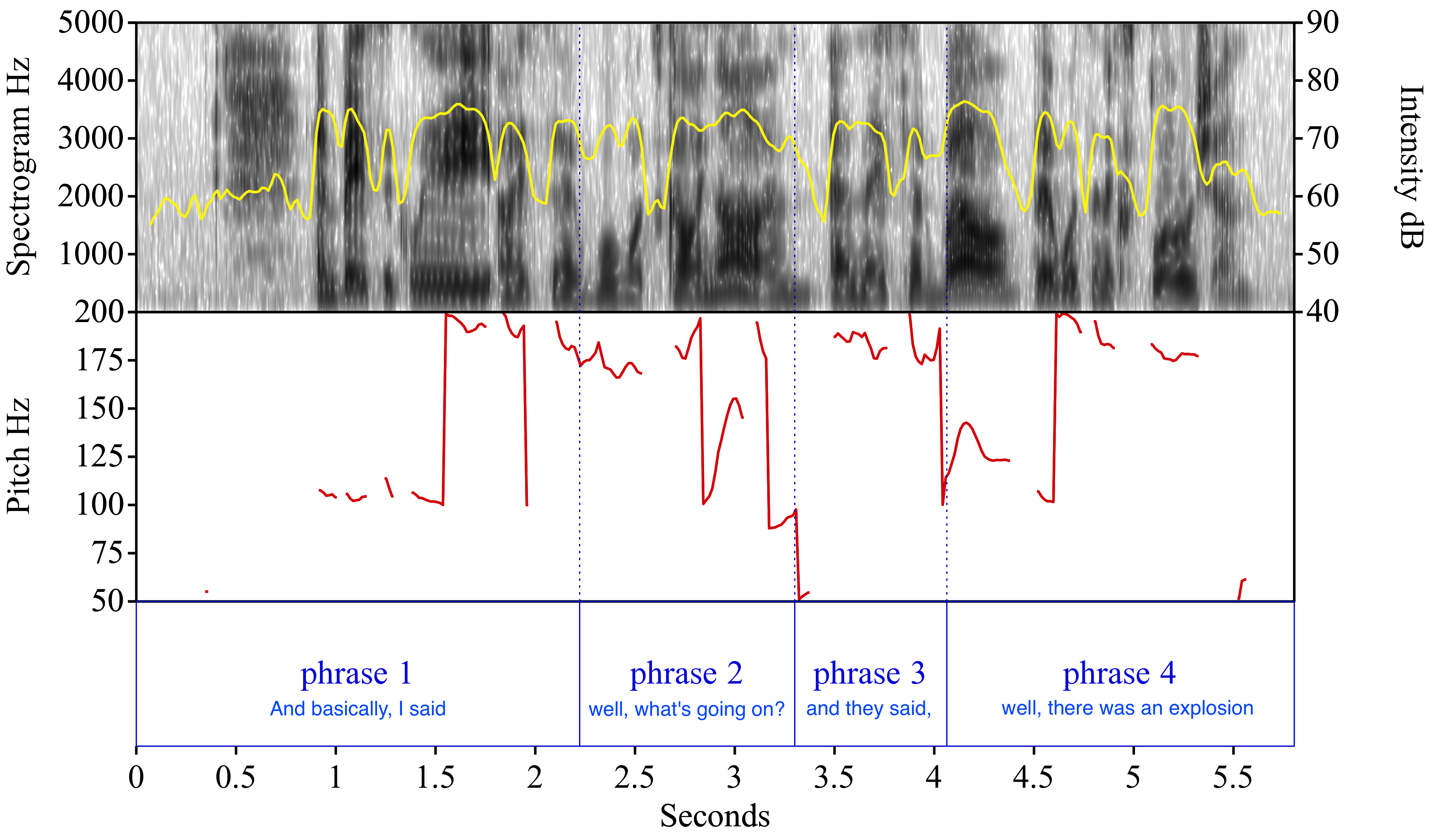
Fig. 31 Recording from Interview with Irene Sadko, New York, New York, November 15, 2001, from the Library of Congress’s “September 11, 2001, Documentary Project”, which is in the public domain.¶
Author’s diagram from Praat.
The top panel displays the spectrogram with its scale on the left, along with a plot of the loudness or intensity of the sound in deciBels, with its scale on the right. The high-frequency spectrogram contrasts with the low-frequency pitch of the speaker’s voice beneath it in red. Her voice barely touches the 90 Hz average of my own. The lower panel splits the sound wave into phrases.
The first phrase ends with a falling pitch, which signals declarative phrases in English. The second phrase also ends falling pitch, typical of questions introduced with an interrogative pronoun in English. The drop is much more abrupt, which is heard as the curious change in intonation of the word “on”. The third phrase repeats the contour of the second, but its force is declarative. The final one ends with a plunge, which signals the end of the entire complex sentence.
Here are three different ways of visualizing my pronunciation of “the first thousand”:
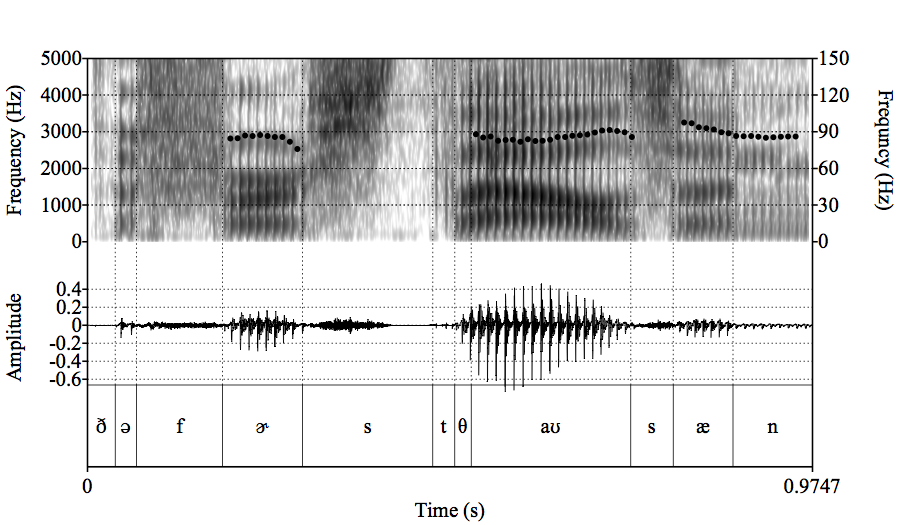
Fig. 32 Visual representation of ‘the first thousand’¶
Author’s image from Praat.
The phones are named across the bottom of the image. The graph above them labeled “Amplitude” displays the sound as a wave oscillating up and down, whose displacement tracks the oscillation of the vocal folds. It is curious to see how uninformative it is. Could you use it to distinguish, say, [f] from [n]?
It is the graph above it, labeled “Frequency (Hz)” on both sides that contains the information which allows us to distinguish [f] from [n], and hopefully from all the other speech sounds, too. This graph analyzes the sound wave into its component frequencies, in two ways. Most of the graph depicts the broad range of frequencies labeled on the left scale. This is what we hear as speech. The three clumps of dots, in contrast, are set on the narrow range of low frequencies labeled on the right scale. This depicts the low intonation of my male voice – note that it averages about 89 Hz. It is such a tiny bit of the full range that it would be smashed down into a featureless line at the very bottom of the graph, which is why it is promoted to its own scale on the right.
The goal of speech perception is to transform the continuous waveforms graphed in the top of the figure into the neat parcellation of symbols in the bottom. The goal of speech comprehension is to figure out what this string of symbols means.
The former may look easy, especially since I have already done it for you. Yet if you look at the frequency plot up close, you will see a transition at each edge that is a mixture of the two abutting segments, neither fully one nor the other. And if you listen to the transitional areas in the recording yourself, you will not hear any such sharply drawn distinctions.
Some phonological processes¶
Voice onset time (VOT)¶
Question
Say the name BP. Do you notice any difference between the first and second consonants?
Below is my pronunciation rendered into Praat. You can download it , too in order to reproduce Fig. 33.
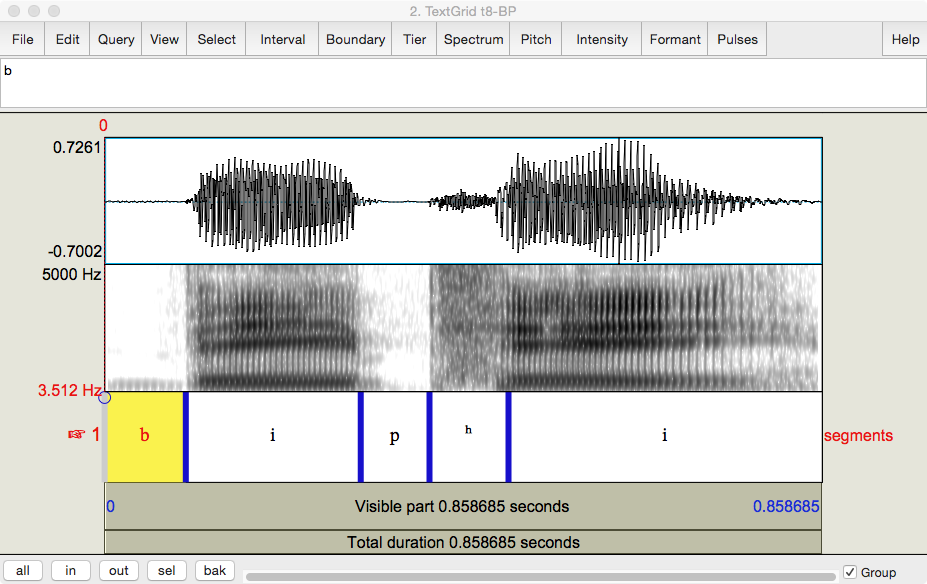
Fig. 33 Author’s pronunciation and transcription of ‘BP’.¶
Screen capture from Praat.
The ‘b’ and the ‘p’ are articulated rather differently. The ‘p’ is followed by a puff of air called aspiration and transcribed as a superscript ‘h’, [ʰ], so that the entire segment would be [pʰ].
Aspiration is not just a quirk of ‘p’.
Question
Pronounce the pairs ‘Dan/tan’ and ‘goon/coon’. Which is aspirated? Refer back to Fig. 26 and try to come up with a succinct statement of which consonants have the potential to be aspirated.
Returning to the bilabial stops,
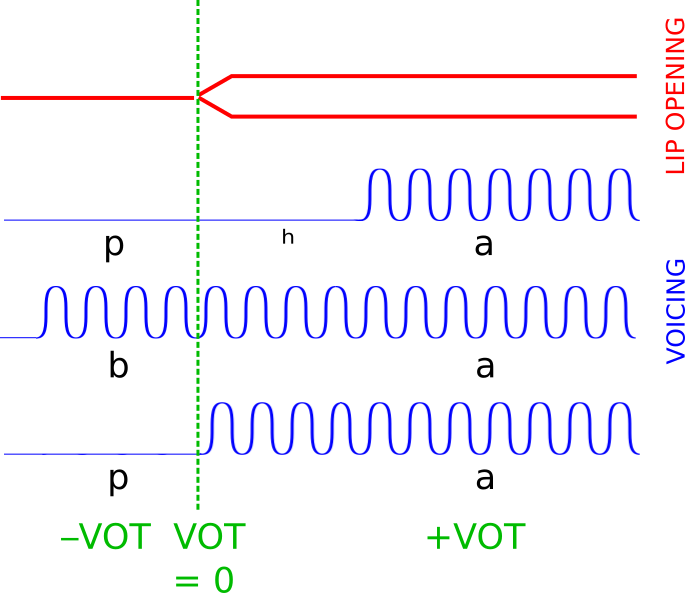
Fig. 34 Difference in voice onset time of [ba], [pa], and [pʰa].¶
Author’s diagram.
Lexical prosody¶
Noun vs. verb in English (±15)
CONvert vs. conVERT
Thai, a tone language
naa with a rising pitch tone means “thick”
naa with a falling pitch tone means “face”
Phrasal prosody¶
Compound noun rule noun phrase: hot DOG (a dog that is hot) adjective+noun: HOTdog (a frankfurter) noun+noun: SHEEPdog (a breed of dogs) Stress retraction After eating fourTEEN, CAKES did not tempt him. After eating FOURteen CAKES, he threw up.
Clausal prosody¶
Contrastive (or emphatic or focal) stress
Examples
The horses were racing from the BARN. The HORSES were racing from the barn.
Sentence type
Types declarative: fall in pitch at end I eat chocolate. interrogative: rise for yes-no question (a); fall for interrogative pronoun (b) Do you eat chocolate? What do you eat? imperative: even pitch throughout; rise in intensity at end Eat chocolate!
Summary¶
References¶
Benward, Bruce and Saker, Marilyn (1997/2003). Music: In Theory and Practice, Vol. I, 7th ed.; p. xiii. McGraw-Hill. ISBN 978-0-07-294262-0.
Endnotes¶
The next topic¶
Come to class having read Perception and answered the questions.
Last edited Aug 18, 2025